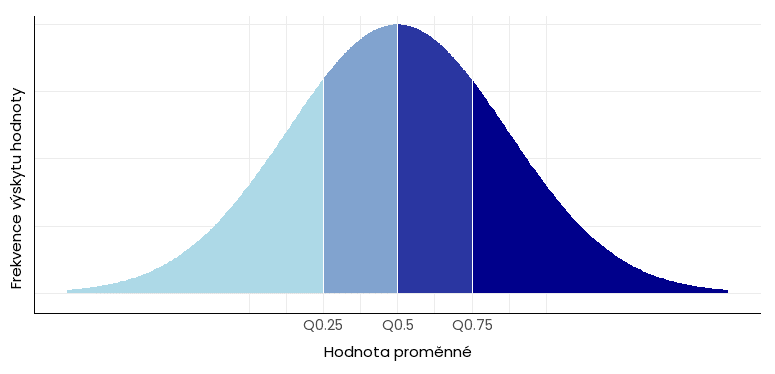
Kvartil je statistická míra polohy, která rozděluje uspořádaný datový soubor do čtyř stejně velkých částí. Existují tři kvartily:
- první kvartil (Q1, také Q0,25) odděluje první čtvrtinu dat od zbytku souboru,
- druhý kvartil (Q2 / Q0,5) rozděluje data na dvě poloviny (v zásadě jde tedy o medián),
- třetí kvartil (Q3 / Q0,75) odčleňuje poslední čtvrtinu dat.
Spolu s dalšími kvantily jej můžete spočítat u kvantitativních proměnných a ordinálních proměnných. U druhé skupiny je výpočet možný za předpokladu rovnoměrného rozložení dat a dostatečného počtu pozorování v každé kategorii (např. u školních známek, kde předpokládáme stejný rozdíl mezi jednotlivými stupni známkování).
Kvartily se počítají podle následujícího vzorce (viz příklad níže):
\( Q_k \) označuje pořadí hodnoty k-tého kvartilu v souboru vzestupně seřazených dat (k = 1 pro první kvartil, k = 2 pro medián a k = 3 pro třetí kvartil).
\( n \) je počet hodnot v datovém souboru. V praxi se kvartily nepočítají ručně, ale s pomocí statistických programů.
V případě, že výsledkem není celé číslo, je potřeba výsledek upravit lineární interpolací mezi dvěma sousedními hodnotami v uspořádaném datovém souboru. Její vzorec je následující (viz příklad níže):
\( x_1 \) a \( x_2 \) je menší, resp. větší pořadí hodnoty, pro které provádíme interpolaci. \( y_1 \) a \( y_2 \) je pak menší, resp. větší hodnota, které interpolujeme.

Pozor – aplikace pro statistickou analýzu, jako je Excel a jazyk R, nevyužívají pro získání výsledku lineární interpolaci, ale složitější postupy. Výsledky se proto mohou od ručního výpočtu lišit.
Využití kvartilů
Kvartily se využívají zejména při vizualizaci dat pomocí boxplotu (krabicového grafu), který poskytuje přehled o rozložení hodnot s ohledem na jejich variabilitu. U datové sady vám pomohou určit střed (medián).
První a třetí kvartil zároveň definuje tzv. mezikvartilové rozpětí (IQR), které udává rozsah prostředních 50 % dat a používá se k detekci odlehlých hodnot.
Existují však situace, kdy kvartily nejsou vhodným nástrojem pro analýzu dat. Zvažte jejich použití, zejména pokud:
- jsou data extrémně variabilní, resp. obsahují mnoho odlehlých hodnot (přestože se právě kvartily používají k jejich identifikaci; příliš mnoho extrémních hodnot výrazně zkresluje i rozložení kvartilů) – potom je třeba zvážit odstranění určitého procenta nejnižších a nejvyšších hodnot,
- pracujete s malým datovým souborem (10 a méně hodnot) – v takovém případě zvolte pro interpretaci dat průměr, medián a rozptyl,
- potřebujete podrobnější informace o rozložení hodnot v datově sadě – zvolte decily či percentily.
Příklad výpočtu kvartilů
Mějme data o dojezdovém čase 19 zaměstnanců do práce (v minutách): 2, 11, 18, 21, 22, 30, 33, 38, 39, 40, 42, 45, 48, 49, 61, 67, 88, 100, 111.
Pro nalezení kvartilů hodnoty nejprve vzestupně seřadíme:
| Pořadí hodnoty | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Dojezdová doba (min) | 2 | 11 | 18 | 21 | 22 | 30 | 33 | 38 | 39 | 40 |
| Pořadí hodnoty | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| Dojezdová doba (min) | 42 | 45 | 48 | 49 | 61 | 67 | 88 | 100 | 111 |
Pro výpočet 1. kvartilu dosadíme tyto hodnoty do výše uvedené rovnice:
Q1 odpovídá 5. hodnotě, tedy 22 minutám.
Stejným způsobem spočítáme i 2., resp. 3. kvartil:
Q2 odpovídá 10. hodnotě (40 min), Q3 odpovídá 15. hodnotě (61 min).
Příklad výpočtu kvartilů s lineární interpolací
Vyjdeme ze stejných dat jako v předchozím příkladu, pouze přidáme navíc jednu hodnotu:
| Pořadí hodnoty | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Dojezdová doba (min) | 2 | 11 | 18 | 21 | 22 | 30 | 31 | 33 | 38 | 39 |
| Pořadí hodnoty | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Dojezdová doba (min) | 40 | 42 | 45 | 48 | 49 | 61 | 67 | 88 | 100 | 111 |
Opět dosadíme hodnoty do vzorce pro výpočet prvního kvartilu:
Pořadí číslo 5,25 (\( x \)) samozřejmě neexistuje. Proto musíme provést lineární interpolaci mezi hodnotami na 5. a 6. místě (\( x_1 \) a \( x_2 \)). Tyto hodnoty (22 a 30 minut, tedy \( y_1 \) a \( y_2 \)) dosadíme do příslušného vzorce (viz výše):
Hodnota 1. kvartilu se tedy rovná 24 minutám. Stejným postupem se u 2. a 3. kvartilu dostaneme k následujícímu pořadí hodnot:
Po použití lineární interpolace pak vychází hodnota 2. kvartilu 40 minut a 3. kvartilu 58 minut.
Výpočet kvartilů v Excelu
# buňky A1 až A100 obsahují naměřené hodnoty
# funkce pro výpočet kvartilů
=QUARTILE(A1:A100, 1) # pro výpočet Q0,25
=QUARTILE(A1:A100, 2) # pro výpočet Q0,5 (medián)
=QUARTILE(A1:A100, 3) # pro výpočet Q0,75Výpočet kvartilů v jazyce R
# naměřené hodnoty
data <- c(3, 5, 6, 7, 8)
# funkce pro výpočet kvartilů
quantile(data, probs = c(0.25, 0.50, 0.75))
# funkce pro výpočet kvartilů lineární interpolací
quantile(data, probs = c(0.25, 0.50, 0.75), type = 6)


