Zpracování popisných charakteristik patří mezi základní úkony při analýze dat. V tomto článku se zaměříme na míry tvaru, které jsou důležitou součástí statistické analýzy dat. Prozkoumáme, k čemu slouží a jak je využít při interpretaci datových souborů. Nezapomeňte se podívat také na detaily o mírách polohy, variability a četnosti.
|
Pro hromadný výpočet souboru různých charakteristik popisné (deskriptivní) statistiky v programovacím jazyce R slouží dvojice příkazů – více informací najdete na konci článku. |
Poznámka: pro výpočet některých měr tvaru a dalších popisných charakteristik v jazyce R budete potřebovat knihovnu e1071, které nainstalujete a otevřete následujícím příkazem:
# instalace knihoven
install.packages(c("e1071", "psych"))Co jsou míry tvaru?
Míry tvaru jsou statistické ukazatele, které poskytují informace o rozdělení hodnot v datové sadě kolem průměru. Pomáhají identifikovat špičatost, asymetrii a další tvarové charakteristiky sledovaných hodnot ve srovnání s normálním rozdělením.
Mezi hlavní míry tvaru patří:
- šikmost,
- špičatost.
Jednotlivé míry tvaru lze spočítat jen u kvantitativních proměnných, nikoliv u kvalitativních.
Na základě získaných hodnot se pak rozhodnete, zda datový soubor např. upravíte na normální rozdělení (třeba logaritmickou transformací), popř. zda k otestování alternativní hypotézy využijete neparametrické testy.

K tomu se hodí znát také míry variability. Pokud totiž např. u více zkoumaných souborů dat zjistíte, že mají normální rozložení, ale odlišné směrodatné odchylky, nelze použít t-test nebo metodu ANOVA.
Šikmost (koeficient šikmosti)
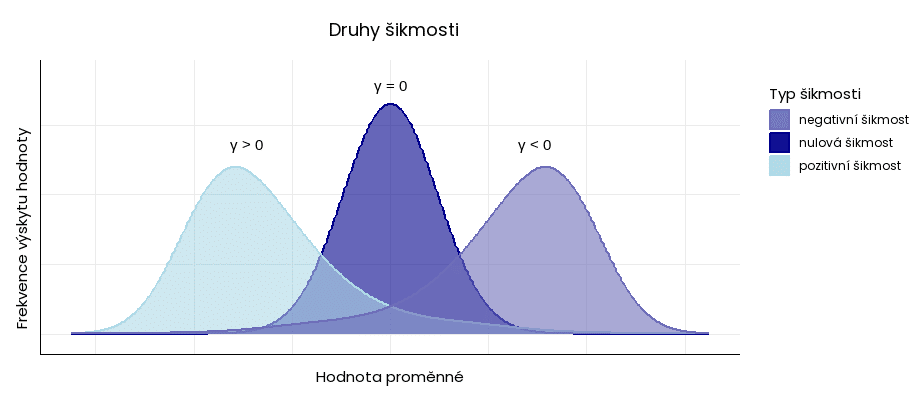
Šikmost (γ) popisuje stupeň asymetrie (nesymetričnosti) datového souboru kolem jeho střední hodnoty. Vyjadřuje se v bezrozměrném koeficientu šikmosti (γ, někdy γ1):
- nulová šikmost (γ = 0) – data mají symetrické rozdělení (jako u normální distribuce); medián se rovná aritmetickému průměru,
- pozitivní (pravostranná) šikmost (γ > 0) – data mají asymetrické rozdělení, většina hodnot se kumuluje nalevo od průměru; medián má nižší hodnotu než aritmetický průměr,
- negativní (levostranná) šikmost (γ < 0) – data mají asymetrické rozdělení, většina hodnot se kumuluje napravo od průměru; medián má vyšší hodnotu než aritmetický průměr.
Počítá se několika způsoby. Mezi nejpoužívanější patří Pearsonův mediánový koeficient šikmosti, který je vhodný pro rychlý odhad šikmosti. Přesnější odhad šikmosti získáte výpočtem tzv. třetího centrálního momentu.
Pearsonův koeficient šikmosti
Pearsonův koeficient šikmosti určuje, kolik směrodatných odchylek dělí průměr a medián daného souboru hodnot:
\( \bar{x} \) značí aritmetický průměr, \( \tilde{x} \) značí medián a \( \sigma \) (sigma) značí směrodatnou odchylku.
Výhody: jednoduchý výpočet pomocí základních statistických charakteristik. Poskytuje způsob, jak rychle posoudit tvar distribuce dat.
Nevýhody: citlivý na odlehlé hodnoty – v některých případech nemusí poskytnout pravdivý obraz asymetrie hodnot. Nelze je použít u multimodálních datových souborů (takové, které mají více než 1 modus).
Excel: funkce pro výpočet Pearsonova koeficientu šikmosti
# buňky A1 až A100 obsahují naměřené hodnoty
# funkce pro výpočet Pearsonova koeficientu šikmosti
=3*(AVERAGE(A1:A100)-MEDIAN(A1:A100))/STDEV.S(A1:A100)R: funkce pro výpočet Pearsonova koeficientu šikmosti
# načtení knihoven
library(e1071)
# naměřené hodnoty
data <- c(3, 5, 6, 7 ,8)
# funkce pro výpočet Pearsonova koeficientu šikmosti
skewness(data, type = 2)Výběrový koeficient šikmosti (třetí centrální moment)
Výběrový koeficient šikmosti slouží k přesnému odhadu o míře asymetrie datového souboru. Počítá se jako tzv. třetí centrální moment:
\( n \) označuje počet hodnot v souboru, \( \bar{x} \) aritmetický průměr a \( \sigma \) (sigma) značí směrodatnou odchylku.
Výhody: Poskytuje hlubší vhled do asymetrie hodnot kolem průměru. Zároveň je méně ovlivnitelný extrémními hodnotami.
Nevýhody: Stejně jako Pearsonův koeficient šikmosti není vhodný pro multimodální datové soubory. Je poměrně obtížný na výpočet – z tohoto důvodu se počítá pomocí softwaru (viz níže).
Excel: funkce pro výpočet výběrového koeficientu šikmosti
# buňky A1 až A100 obsahují naměřené hodnoty
# funkce pro výpočet výběrového koeficientu šikmosti
=SKEW(A1:A100)R: funkce pro výpočet výběrového koeficientu šikmosti
# načtení knihovny
library(e1071)
# naměřené hodnoty
data <- c(3, 5, 6, 7 ,8)
# funkce pro výpočet Pearsonova koeficientu šikmosti
skewness(data)Špičatost (koeficient špičatosti)
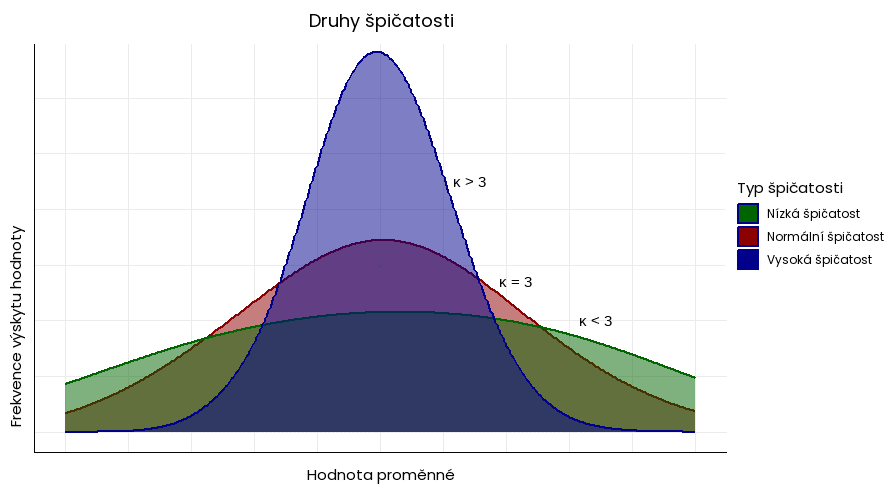
Špičatost popisuje míru koncentrace dat kolem střední hodnoty ve srovnání s normální distribucí. Vyjadřujeme ji v bezrozměrném koeficientu špičatosti (κ, někdy také γ2):
- normální (mezokurtická) špičatost (κ = 3) – hodnoty vykazují stejnou špičatost jako normální distribuce dat.
- vysoká (leptokurtická) šikmost (κ > 3) – distribuce dat vykazuje vyšší a užší vrchol a těžší ocasy ve srovnání s normálním rozdělením.
- Nízká (platykurtická) šikmost (κ < 3) – Distribuce dat vykazuje nižší a širší vrchol a lehčí ocasy ve srovnání s normálním rozdělením.
Řada aplikací pracuje s tzv. přebytečnou (excesivní) špičatostí, kdy od výsledné hodnoty odečítá číslo 3. Normální špičatost se potom rovná 0, vysoká je vyšší než 0 a nízká nižší než 0.
Špičatost se počítá podle tzv. čtvrtého centrálního momentu:
\( n \) označuje počet hodnot v souboru, \( x_i \) hodnota jednotlivých dat v souboru, \( \bar{x} \) aritmetický průměr a \( \sigma \) (sigma) značí směrodatnou odchylku.
Excesivní špičatost spočítáte odečtením hodnoty 3.
Výhody: Špičatost poskytuje informace o tvaru rozdělení dat, které nelze zachytit jinými charakteristikami, jako je průměr a směrodatná odchylka.
Nevýhody: Špičatost je citlivá na odlehlé hodnoty a může být obtížně interpretovatelná, zejména u malé velikosti vzorku.
Excel: funkce pro výpočet koeficientu špičatosti
# buňky A1 až A100 obsahují naměřené hodnoty
# funkce pro výpočet koeficientu špičatosti
=KURT(A1:A100)R: funkce pro výpočet koeficientu špičatosti
# načtení knihovny
library(e1071)
# naměřené hodnoty
data <- c(3, 5, 6, 7 ,8)
# funkce pro výpočet koeficientu špičatosti
kurtosis(data)Hromadný výpočet souboru popisných charakteristik v jazyce R
Pro získání základního přehledu o vlastnostech datového souboru slouží příkaz summary(), rozsáhlejší přehled získáte příkazem describe().
Příkazem summary() vypočítáte:
- minimální a maximální hodnotu datového souboru,
- hodnotu 1. a 3. kvartilu a mediánu (tedy 25., 50. a 75. percentil),
- aritmetický průměr,
- počet pozorování pro jednotlivé kategorie/úrovně (u nominálních a ordinálních proměnných).
# naměřené hodnoty
data <- c(3, 5, 6, 7, 8)
# výpočet souboru popisných charakteristik s funkcí summary
summary(data)Příkazem describe() (je součástí balíčku psych, který je třeba nainstalovat a načíst) spočítáte:
- počet platných a chybějících pozorování,
- minimální a maximální hodnotu datového souboru a jeho rozsah,
- medián (50. percentil) a medián absolutních odchylek,
- aritmetický průměr a a oříznutý průměr (průměr po odstranění určitého procenta nejnižších a nejvyšších hodnot),
- směrodatnou odchylku a směrodatnou chybu průměru,
- špičatost datového souboru (rozložení hodnot v porovnání s normální distribucí),
- šikmost datového souboru.
# načtení knihovny
library(psych)
# naměřené hodnoty
data <- c(3, 5, 6, 7, 8)
# výpočet souboru popisných charakteristik s funkcí describe
describe(data)