Modus je míra polohy vyjadřující nejčastější hodnotu (frekvenci výskytu) zkoumané proměnné. Při výskytu jednoho modu označujeme datový soubor jako unimodální, u dvou modů jako bimodální a u více modů jako multimodální.
Modus lze spočítat u různých typů proměnných:
- nominální data – např. nejčastější vedlejší účinek u experimentálního léku na gliom,
- ordinální data – nejčastější stádium gliomu, se kterým pacienti přicházejí k lékaři,
- diskrétní proměnné – nejčastější počet léčebných cyklů podaný pacientovi,
- spojité proměnné – nejčastější koncentrace experimentálního léku v krvi hodinu po podání.
U nominálních, ordinálních a diskrétních dat jej zjistíte spočítáním četnosti jednotlivých hodnot (viz příklad níže):
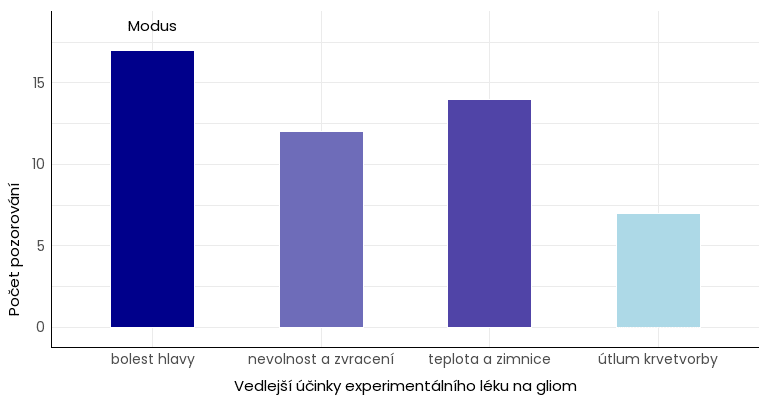
Příklad modu u nominální proměnné.
Pro spojité proměnné lze navíc konkrétní hodnotu vypočítat vzorcem tzv. aproximace módu v intervalových datech (viz příklad níže):
\(L \) označuje dolní hranici modálního intervalu (intervalu s nejvyšší četností), \(f_1 \) četnost modálního intervalu, \(f_0 \) četnost intervalu před modálním intervalem, \(f_2 \) četnost intervalu za modálním intervalem a \(h \) šířku intervalů.
Pozor – aplikace pro statistickou analýzu, jako je Excel a jazyk R, nevyužívají pro získání výsledku aproximaci v intervalových datech, ale složitější postupy. Výsledky se proto mohou od ručního výpočtu lišit.

Příklad modu u spojité proměnné, která nabývá v určitém rozsahu libovolných hodnot – pro účely vizualizace se proto zobrazuje počet hodnot v rámci určitých intervalů.
V praxi se medián nepočítá ručně, ale s pomocí statistických programů.

Poznámka: pro výpočet modu v jazyce R budete potřebovat knihovny rstatix a DescTools, které nainstalujete následujícím příkazem:
# instalace knihoven
install.packages(c("rstatix", "DescTools"))Využití modu
Na rozdíl od průměru a mediánu lze modus použít i pro nečíselné proměnné v různých oborech:
- zdravotnictví – nejčastější typu určitých příznaků onemocnění nebo vedlejších účinků studovaného léku,
- sociologie – nejčastější dosažené vzdělání,
- ekonomie – nejvíce kupovaná značka určitého druhu zboží,
- geografie – nejčastější typ půdy v oblasti.
Spojité kvantitativní proměnné jsou při určování modu citlivé na šířku intervalu. Je proto třeba zvolit vhodnou metodu pro výpočet této šířky – často se využívá např. Sturgesovo pravidlo (viz níže).
Příklad výpočtu modu – ordinální proměnná
Vaším úkolem je určit modus stádia gliomu, se kterým pacienti poprvé přijdou do ordinace. K dispozici máte vzorek 20 nemocných, u kterých lékař diagnostikoval stádium nádoru:
| Pořadí pacienta | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Stádium gliomu | III | II | IV | II | III | IV | I | II | III | IV |
| Pořadí pacienta | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Stádium gliomu | II | I | III | IV | II | I | III | IV | I | II |
Nejprve hodnoty seřadíme: I, I, I, I, II, II, II, II, II, II, II, II, III, III, III, III, III, III, IV, IV, IV, IV
Poté určíme jejich četnost výskytu:
- Stádium I: 4×,
- Stádium II: 8×,
- Stádium III: 6×,
- Stádium IV: 4×.
Modus datového souboru je stádium II.
Výpočet modu v Excelu
V Excelu můžete pro nalezení modu použít dvě funkce:
- Funkce MODE je vhodná v situaci, kdy soubor hodnot obsahuje pouze jeden modus; v opačném případě vrátí pouze první nalezený modus.
- Funkce MODE.MULT vrátí všechny nalezené mody; je tedy ideální pro situace, kdy počet očekávaný modů neznáte nebo jich očekáváte více.
# buňky A1 až A100 obsahují naměřené hodnoty
# funkce pro výpočet prvního modu
=MODE(A1:A100)
# funkce pro výpočet všech modů
=MODE.MULT(A1:A100)Výpočet modu v jazyce R
Pro nalezení modu v jazyce R můžete využít tyto funkce:
- get_mode z balíčku rstatix vrátí hodnoty všech modů,
- Mode z balíčku DescTools vrátí 1) hodnoty všech modů, 2) početní zastoupení těchto hodnot.
# načtení knihoven
library(rstatix)
library(DescTools)
# naměřené hodnoty
data <- c("Male", "Female", "Female", "Female", "Male")
# funkce pro výpočet modu
get_mode(data)
# funkce pro výpočet modu a početního zastoupení modu
Mode(data)Příklad výpočtu modu – spojitá proměnná
Máte za úkol vypočítat modus koncentrace nádorových markerů v krvi pacienta s gliomem. Datová sada obsahuje následujících 20 hodnot:
| Pořadí pacienta | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Koncentrace markerů (ng/ml) | 5,2 | 6,9 | 5,5 | 6,0 | 5,9 | 7,1 | 6,5 | 5,8 | 6,3 | 7,0 |
| Pořadí pacienta | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Koncentrace markerů (ng/ml) | 5,7 | 6,6 | 5,4 | 6,1 | 7,2 | 6,4 | 5,6 | 6,7 | 5,3 | 6,9 |
Pracujeme se spojitými proměnnými, proto je nejprve třeba určit počet intervalů a jejich šířku. K tomu slouží Sturgesova pravidlo:
\(k \) vyjadřuje počet intervalů a \(n \) počet hodnot (pozorování) v datovém souboru. Pokud hodnota \(k \) není celočíselná, zaokrouhlíme ji nahoru. Po dosazení vychází:
Po zaokrouhlení nahoru se tedy \(k \) rovná 6 – hodnoty našeho souboru zobrazíme v 6 intervalech.
Pro určení šířky intervalu (\(h\)) spočítáme rozpětí hodnot v datovém souboru (\(R\)) a vydělíme jej počtem intervalů (\(k\)).
Víme, že nejnižší hodnota (\(x_{\text{min}}\)) je 5,2 ng/ml a nejvyšší hodnota (\(x_{\text{max}}\)) je 7,2 ng/ml:
Rozpětí (\(R\)) je tedy 2,0 ng/ml. Dosadíme získané hodnoty do vzorce pro výpočet šířky intervalu:
Jednotlivé intervaly mají tedy přibližně tento rozsah:
| Pořadí intervalu | 1 | 2 | 3 | 4 | 5 | 6 |
| Rozsah koncentrace (ng/ml) | 5,2–5,53 | 5,53–5,86 | 5,86–6,19 | 6,19–6,52 | 6,52–6,85 | 6,85–7,2 |
Nakonec spočítáme četnost výskytu hodnot v jednotlivých intervalech:
- 1. interval (5,2–5,53 ng/ml) – 5,2 ng/ml, 5,3 ng/ml, 5,4 ng/ml, 5,5 ng/ml (4 hodnoty),
- 2. interval (5,53–5,86 ng/ml) – 5,6 ng/ml, 5,7 ng/ml, 5,8 ng/ml (3 hodnoty),
- 3. interval (5,86–6,19 ng/ml) – 5,9 ng/ml, 6,0 ng/ml, 6,1 ng/ml (3 hodnoty),
- 4. interval (6,19–6,52 ng/ml) – 6,3 ng/ml, 6,4 ng/ml, 6,5 ng/ml (3 hodnoty),
- 5. interval (6,52–6,85 ng/ml) – 6,6 ng/ml, 6,7 ng/ml (2 hodnoty),
- 6. interval (6,85–7,2 ng/ml) – 6,9 ng/ml, 6,9 ng/ml, 7,0 ng/ml, 7,1 ng/ml, 7,2 ng/ml (5 hodnot).
Modální interval datového souboru je 6,85–7,2 ng/ml. Datový soubor je tedy unimodální.
Přesnou hodnotu modu spočítáme metodou aproximace (viz výše).
Dolní hranice modálního intervalu (\(L \)) je 6,85 ng/ml, četnost modálního intervalu (\(f_1 \)) je 5, četnost intervalu před modálním intervalem (\(f_0 \)) je 2, četnost intervalu za modálním intervalem (\(f_2 \)) je 0 (za modálním intervalem žádný další interval nemáme) a zmiňovaná intervalu (\(h \)) je 0,33.
Dosadíme tedy do vzorce:
Modus koncentrace nádorových markerů je tedy 6,97 ng/ml.
Výpočet modu spojité proměnné v jazyce R
Modus spojité proměnné v R zjistíte výpočtem maxima tzv. kernelové hustoty:
# naměřené hodnoty
data <- c(5.2, 6.9, 5.5, 6.0, 5.9, 7.1, 6.5, 5.8, 6.3, 7.0)
# funkce pro odhad kernelové hustoty
dens <- density(data)
# funkce pro nalezení maxima kernelové hustoty
mode_value <- dens$x[which.max(dens$y)]
# výstup modu
mode_value

