Zpracování dat (anglicky data wrangling nebo data munging) je soubor postupů, díky terým transformujete surová data z experimentů do podoby vhodné pro statistickou analýzu, ověření vaší alternativní hypotézy, vizualizaci či modelování.
Platí: čím lépe data zpracujete, tím kvalitnějších výstupů dosáhnete.
Pro data wrangling se ve vědecké komunitě často používá programovací jazyk R, navržený přímo pro statistickou analýzu. Mezi jeho výhody patří:
- flexibilita – R nabízí širokou škálu balíčků a funkcí pro různé typy analýz a vizualizací, což vám dává možnost přizpůsobit nástroje konkrétním potřebám projektu,
- konzistence – Sady balíčků jako tidyverse poskytují jednotný a intuitivní přístup k manipulaci s daty, což usnadňuje práci a zvyšuje čitelnost kódu,
- vizualizační schopnosti – balíčky jako ggplot2 umožňují vytvářet komplexní a estetické vizualizace, které usnadňují interpretaci výsledků,
- integrace s dalšími nástroji – R snadno propojíte s dalšími nástroji a programovací jazyky, jako jsou Python, SQL a různé databázové systémy,
bezplatný přístup – jazyk R je open-source a zdarma – za jeho používání nic neplatíte.

Ukázka prostředí jazyka R
- editor skriptů (Script) – pro psaní, úpravu a ukládání R skriptů s funkcemi jako barevné zvýraznění syntaxe a automatické doplňování kódu.
- konzole (Console) – pro zadávání a spouštění příkazů v R,
- okno prostředí (Environment) – pro zobrazení aktuálně nahraných objektů (Environment) a historie zadaných příkazů (History).
- okno prohlížeče (Output) – pro procházení souborů (Files), zobrazení grafických výstupů (Plots), správu balíčků (Packages), přístup k dokumentaci a nápovědě (Help) a zobrazení interaktivních výstupů (Viewer).
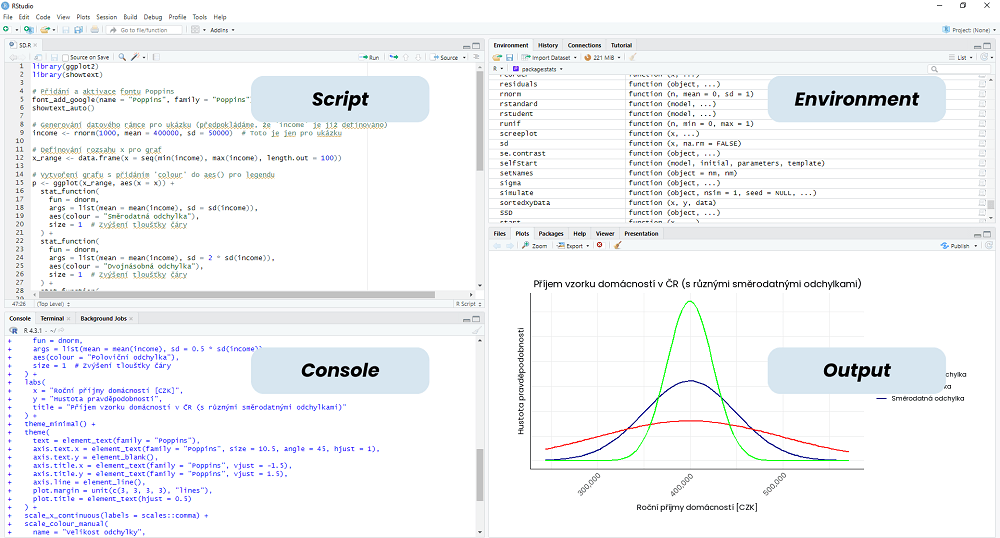
Ukázka prostředí RStudio
Script, nebo Console?Psaní vlastních skriptů v okně Script je oproti opakovanému opisovaní kódu do okna Console výhodnější. Skript je přehlednější a kód ve skriptu snadno uložíte. To je pro opakované použití a zejména reprodukovatelnost analýzy ve vaší výzkumné práci naprosto zásadní. |
Základní syntax jazyka R
Psaní kódu navrhli tvůrci jazyka R tak, aby bylo co nejvíce intuitivní a pochopitelné i pro ty, kteří se programováním neživí. Základem jsou funkce, které obsahují argumenty. K těm přiřazujeme různé hodnoty.
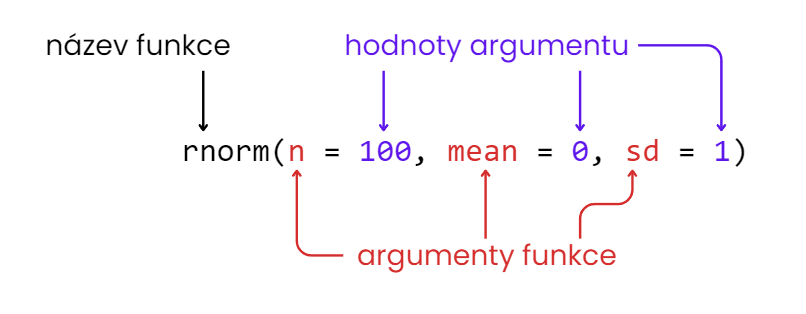
Struktura funkcí v jazyce R
Pro zjištění, jaké argumenty s jakými hodnotami můžete do funkce vložit, slouží příkaz ‚?nazev-funkce‘ (dokáže zobrazit také informace o datovém objektu, resp. sadě) – probíráme jej níže.

Přiřazování hodnot proměnné
Základním příkazem je přiřazení určité hodnoty k určitému objektu (viz níže). K tomu se využívá symbol ‚<-‘, popř. ‚=‘ (ten ale není z technických důvodů vhodný). Způsob přiřazení více hodnot najdete o několik řádků níže.
# přiřazení jedné hodnoty (objektu x se přiřadí hodnota 5)
x <- 5
x = 5Tyto přiřazené hodnoty se ukládají a zobrazují v okně Environment:

V paměti aktuální relace má objekt x přiřazenou hodnotu (value) 5, objekt y hodnotu 10 a objekt z hodnotu 15. V okně Environment zároveň zjistíte, o jaký typ objektu jde (detailněji rozebíráme níže), kolik hodnot je k němu přiřazeno (length) a kolik paměti zabírá (size).
Datové typy a objekty
V R můžete pracovat s mnoha různými datovými typy (typy proměnných). Na rozdíl od jiných programovacích jazyků je nemusíte specifikovat – R si datový typ určí sám. Mezi základní patří:
a <- 10 # numerický typ (numeric)
b <- factor("text") # kategorická proměnná (factor)
c <- "text" # text (character)
d <- TRUE # logická hodnota (boolean)
Rozdíl mezi textem a kategorickou proměnnou v RV R se text (character) používá k uchovávání a manipulaci s textovými daty, zatímco kategorická proměnná (factor) slouží k uchovávání kategoriálních dat s definovanými hodnotami. Datový typ factor navíc ukládá pořadí hodnot, což umožňuje efektivní analýzu kategoriálních dat, protože R s nimi může zacházet jako s diskrétními hodnotami. To je užitečné pro statistické analýzy a vizualizace, protože můžete nastavit řazení hodnot např. v grafu. Pro data typu character nelze nastavit pořadí hodnot – řadí se vždy abecedně. |
Datové objekty (struktury)
R pracuje s různými datovými objekty (strukturami), z nichž nejdůležitější jsou:

Zdroj: venus.ifca.unican.es, upraveno
Vektor (vector) – jednorozměrné pole, které obsahuje prvky stejného datového typu. Vytváří se pomocí funkce ‚c()‘, např. ‚c(1, 2, 3)‘:
# vytvoří vektor s hodnotami 1 až 3 a přiřadí je proměnné v
v <- c(1, 2, 3)Matice (matrix) – dvourozměrné pole s prvky stejného datového typu. Vytváří se pomocí funkce ‚matrix()‘, např. ‚matrix(1:6, nrow = 2, ncol = 3)‘:
# vytvoří matici s hodnotami 1 až 6 ve dvou řádcích a třech sloupcích a přiřadí je proměnné m
m <- matrix(1:6, nrow = 2, ncol = 3)Pole (array) – vícerozměrné pole s prvky stejného datového typu. Vytváří se pomocí funkce ‚array()‘, např. ‚array(1:12, dim = c(2, 3, 2))‘:
# vytvoří pole s hodnotami 1 až 12 ve tvaru 2 × 3 × 2 a přiřadí jej proměnné a
a <- array(1:12, dim = c(2, 3, 2))Seznam (list) – jednorozměrné pole s prvky různých datových typů. Vytváří se pomocí funkce ‚list()‘, např. ‚list(1, „hello“, TRUE)‘:
# vytvoří list s hodnotami 1, hello a TRUE a přiřadí je proměnné l
l <- list(1, "hello", TRUE)Datový rámec (data frame) – tabulky s řádky a sloupci, kde každý sloupec může mít jiný datový typ. Vytváří se pomocí funkce ‚data.frame()‘, např.‚data.frame(jméno = c(„Anna“, „Petr“), věk = c(25, 30))‘:
# vytvoří datový rámec se dvěma sloupci (jméno a věk) a přiřadí je proměnné df
df <- data.frame(jméno = c("Anna", "Petr"), věk = c(25, 30))Základní funkce pro práci s RStudio
Nyní, když rozumíte podstatě datových objekt, podívejme se na některé užitečné funkce pro práci s RStudio:
‚data()‘ – zobrazí v okně Script záložku s výpisem datových sad, které máte k dispozici pro experimentování.
data()
Seznam dostupných datových sad
‚?nazev-funkce‘, např. ‚?mean‘ – zobrazí v okně Output v záložce Help základní informace o dané funkci a jejích možných argumentech (v tomto případě pro průměr).
?nazev-funkce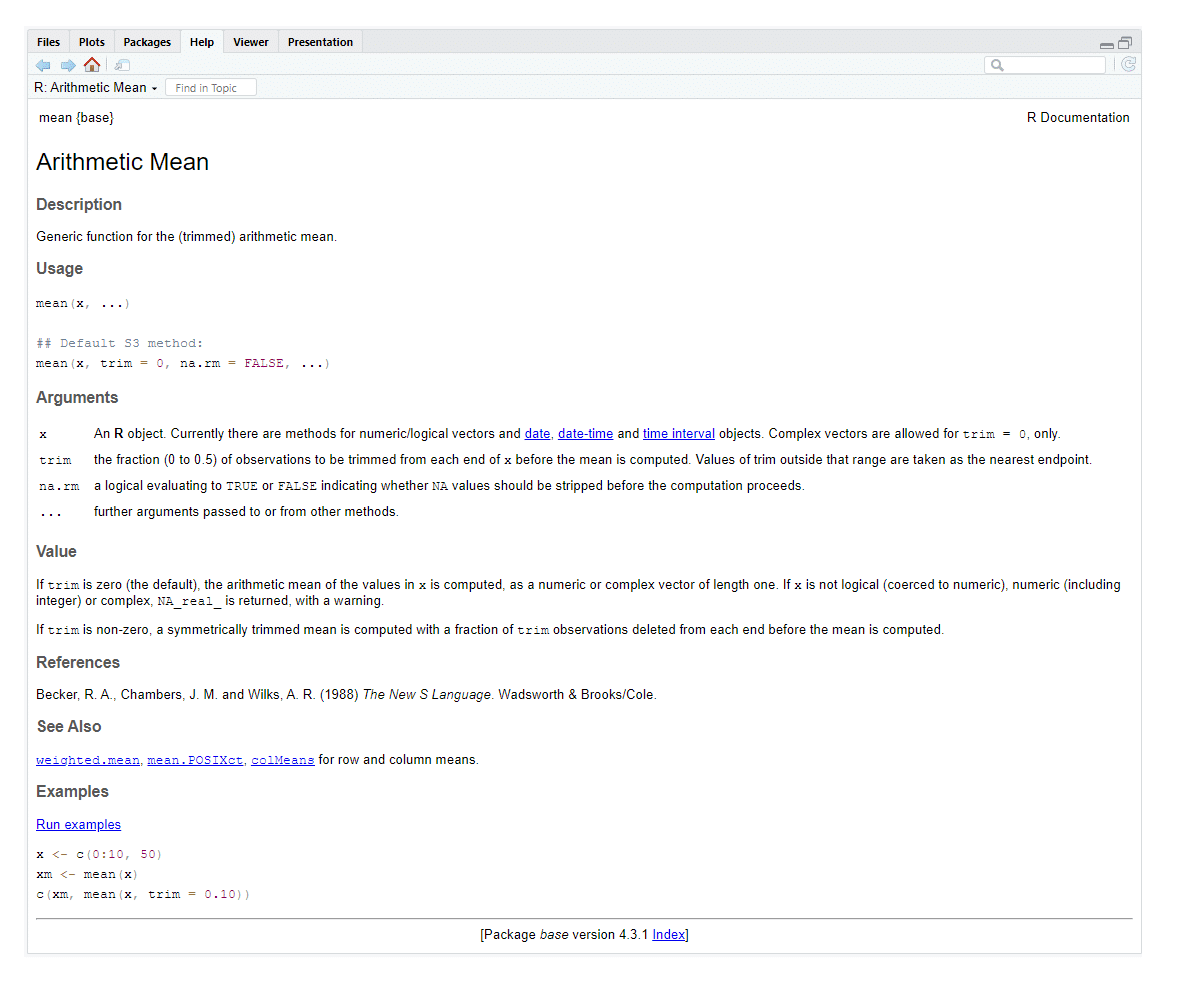
Popis funkce ‚mean‘ s možnými argumenty a hodnotami, praktickým příkladem, dalšími doporučenými funkcemi a literaturou, ze které funkce ‚mean‘ vychází
‚View(nazev-objektu)‘, např. ‚View(CO2)‘ – otevře v okně Script záložku s tabulkou daného objektu (v tomto případě tabulka s hodnotami příjmu oxidu uhličitého trávou). Stejným způsobem zobrazíte jakoukoliv sadu, kterou do R importujete, popř. datovou strukturu, kterou vytvoříte.
View(nazev-objektu)
Výpis obsahu objektu – datové sady CO2 v okně Console
‚nazev-objektu‘, např. ‚CO2‘ – funguje podobně jako funkce ‚View()‘, objekt ale zobrazí pouze v okně Console. Je tak vhodná pro rychlý přehled o obsahu objektu.
nazev-objektu
Výpis obsahu objektu – datové sady CO2 v okně Console
‚summary(nazev-objektu)‘, např. ‚summary(CO2)‘ – zobrazí v okně Console vybrané popisné statistiky (základní míry polohy a míry variability) pro všechny sloupce daného objektu.
summary(nazev-objektu)
Základní míry polohy a variability objektu – datové sady CO2
‚head(nazev-objektu)‘, např. ‚head(CO2)‘ – zobrazí v okně Console prvních několik řádků daného objektu (hodí se např. pro rychlou kontrolu struktury a obsahu dat).
head(nazev-objektu)
Prvních několik řádků objektu – datové sady CO2
‚str(nazev-objektu)‘, např. str(CO2)‘ – zobrazí v okně Console strukturu datového objektu, včetně typů dat a základních informací o každém sloupci.
str(nazev-objektu)
Struktura proměnných datové sady CO2
‚install.packages(„nazev-balicku“)‘, např. ‚install.packages(„tidyverse“)‘ – nainstaluje nový balíček (v tomto případě soubor základních balíčků z tidyverse).
# instalace jednoho balíčku
install.packages("nazev-balicku")
# instalace více balíčků
install.packages(c("balicek1", "balicek2", "balicek3"))‚library(nazev-balicku)‘, např. ‚library(tidyverse)‘ – načte nainstalovaný balíček do aktuálního pracovního prostředí, což umožňuje použití jeho funkcí a dat (v tomto případě soubor základních balíčků z tidyverse). Pro načtení více balíčku je potřeba funkci vždy zopakovat.
# načtení jednoho balíčku
library(nazev-balicku)
# načtení více balíčků
library(nazev-balicku1)
library(nazev-balicku2)
library(nazev-balicku3)
S uvozovkami, nebo bez?Uvozovky je třeba použít, pokud funkce v R očekává jako vstup (argument) textový řetězec (character), například ‚install.packages(„tidyverse“)‘. Pokud ale voláte funkci nebo struktury (resp. objekty – viz níže), které jsou součástí základních nebo již načtených balíčků R, uvozovky používat nemusíte. To platí i pro již nainstalované knihovny, proto je argument funkce library bez uvozovek, např. ‚library(tidyverse)‘. Obecně tedy platí, že pokud funkce očekává název, použijte řetězec, jinak předpokládá, že jde o již existující objekt v prostředí. |
Řídící struktury
R využívá řadu logických příkazů pro řízení toku programu, např. podmínky ‚if‘ a ‚else‘ nebo cykly ‚for‘ a ‚while‘:
# podmínka pro zobrazení jedné z variant textu
if (x > 5) {
print("x je větší než 5")
} else {
print("x je menší nebo rovno 5")
}Jak vidíte výše, v R se setkáte také s řadou logických operátorů, jako AND (&&, &), OR (||, |), NOT (!), rovnost (==), nerovnost (!=), menší než (<), větší než (>), menší nebo rovno (<=) a větší nebo rovno (>=).
Co je tidyverse?
Tidyverse je soubor R balíčků (rozšíření) navržených pro datovou vědu, které sdílejí společnou filozofii návrhu, syntaxu a datové struktury. Tento ekosystém poskytuje výrazně zjednodušuje proces zpracování dat, zvyšuje produktivitu a šetří čas pro vlastní výzkum.
Do těchto balíčků řadíme:
- readr – pro rychlý a snadný import dat ve formátu csv a tsv,
- tibble – moderní alternativa k datovým rámcům, zlepšující přehlednost a konzistenci,
- dplyr – manipulace s datovými rámci (výběr, filtrování, agregace),
- tidyr – restrukturalizace a formátování dat (pivoting, melting),
- stringr – manipulace s textovými řetězci,
- forcats – práce s kategorickými proměnnými,
- purrr – funkcionální programování a práce s vektory a seznamy,
- ggplot2 – vizualizace dat a tvorba komplexních a přizpůsobitelných grafů.
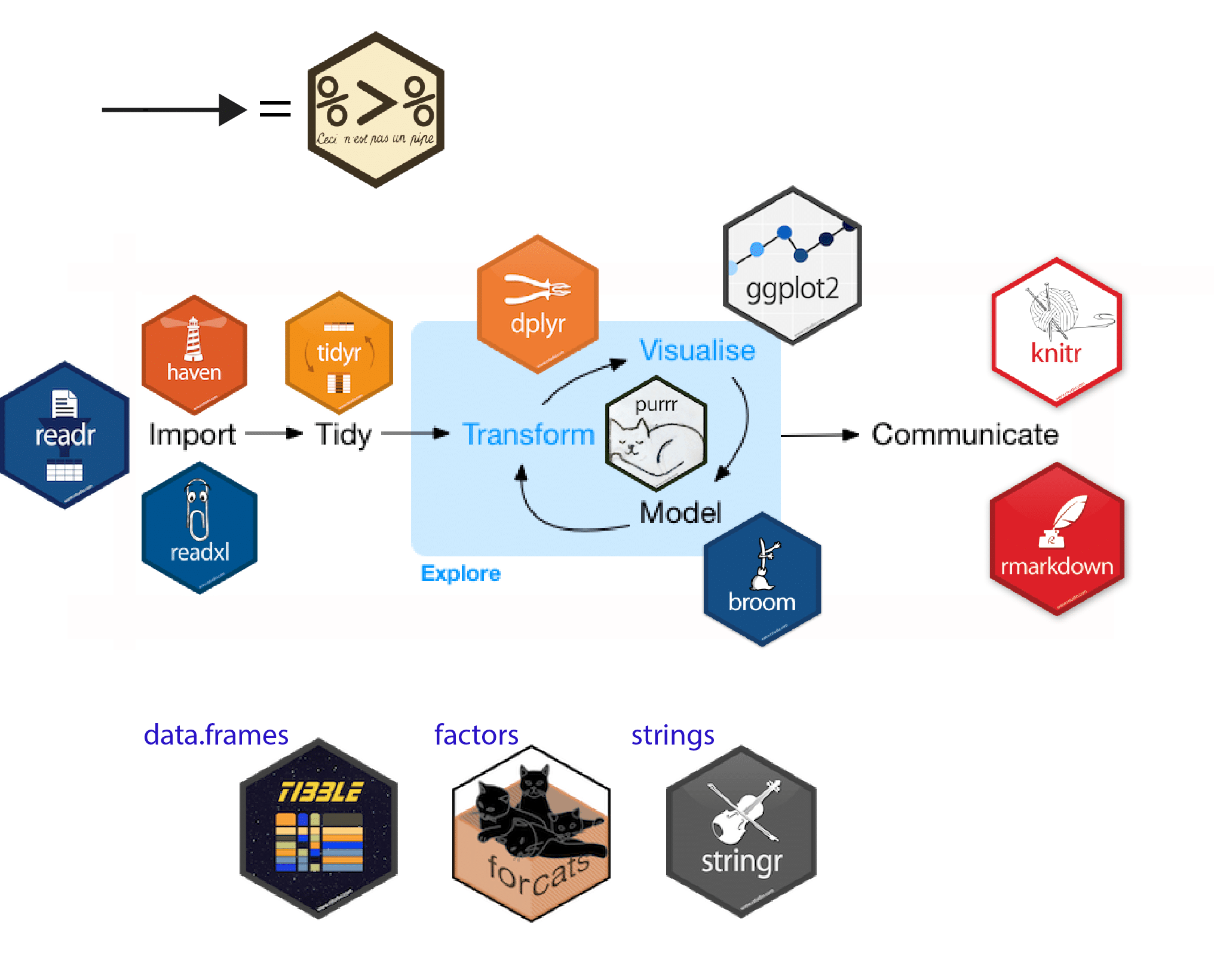
Logika ekosystému tidyverse. Zdroj:oliviergimenez.github.io
Datový tok (pipelines)
Jedním z klíčových konceptů tidyverse je datový tok (pipeline), který umožňuje propojovat funkce do sekvencí a zpracovávat data intuitivním a přehledným způsobem. K tomu slouží tzv. pipe operátor ‚%>%‘. Zapíšete jej pomocí zkratky CTRL + SHIFT + M.
Pipe operátor ‚%>%‘ předává výstup jedné funkce jako vstup do další funkce. To umožňuje psát kód, který se čte jako sled kroků aplikovaných na data. Tímto způsobem si zároveň mohou jednotlivé balíčky tidyverse předávat data k postupnému zpracování.
Proč je to důležité?
Ve standardním prostředí jazyka R se pro předání na další funkci musí jednotlivé výstupy ukládat do dalších a dalších datových struktur.
V prvním případě vypadá načtení datasetu (výše zmíněného CO2), vyfiltrování hodnot určité proměnné (conc – koncentrace CO2 v okolním vzduchu v ml/l), výběr určitých sloupců (conc a uptake – spotřeba CO2 určitou rostlinou v μmol/m2.s) a seřazení řádků podle spotřeby (uptake) takto:
# instalace balíčku dplyr (pokud ještě není nainstalovaný)
install.packages("dplyr")
# Načtení balíčku dplyr
library(dplyr)
# Načtení datasetu CO2 a vyfiltrování hodnot proměnné conc větší než 500
filtered_data <- filter(CO2, conc > 500)
# Výběr sloupců conc a uptake
selected_data <- select(filtered_data, conc, uptake)
# Seřazení řádků vzestupně podle proměnné uptake
sorted_data <- arrange(selected_data, uptake)
# Zobrazení výsledné datové struktury v okně Script
View(sorted_data)Druhou možností je použití zanořených funkcí. Tato varianta je ale nepřehledná a snadno v ní uděláte chybu:
# Načtení balíčku dplyr
library(dplyr)
# Použití zanořených funkcí
sorted_data <- arrange(select(filter(CO2, conc > 500), conc, uptake), uptake)
# Zobrazení výsledné datové struktury v okně Script
View(sorted_data)Při použití pipe operátoru se výstupy jednotlivých funkcí ihned předají následující funkci:
# Načtení balíčku dplyr
library(dplyr)
# Zařazení datové sady do pipe operátoru
CO2 %>%
# Načtení datasetu CO2 a vyfiltrování hodnot proměnné conc větší než 500
filter(conc > 500) %>%
# Výběr sloupců conc a uptake
select(conc, uptake) %>%
# Seřazení řádků vzestupně podle proměnné uptake
arrange(uptake) %>%
# Zobrazení výsledné datové struktury v okně Script
View()Všimněte si, že u poslední funkce ‚View‘ není žádný argument – funkce totiž zobrazí datovou strukturu, kterou jí pipe operátor doručil.
Pokud byste ale výsledné hodnoty chtěli uložit do datové struktury, provedete to následujícím způsobem:
# Načtení balíčku dplyr
library(dplyr)
# Zařazení datové sady do pipe operátoru a přiřazení výsledku do struktury up_CO2
up_CO2 <- CO2 %>%
# Načtení datasetu CO2 a vyfiltrování hodnot proměnné conc větší než 500
filter(conc > 500) %>%
# Výběr sloupců conc a uptake
select(conc, uptake) %>%
# Seřazení řádků vzestupně podle proměnné uptake
arrange(uptake)
# Zobrazení výsledné datové struktury v okně Script
View(up_CO2) Naučte se ovládat jazyk R pod dohledem zkušeného lektora
Kurz ovládání programovacího jazyka R pořádáme pravidelně v Praze i na dalších místech. Během 1denního kurzu se kromě základních funkcí naučíte do jazyka R data importovat, upravit je, analyzovat a nakonec vizualizovat.
Lektorem kurzu je Mgr. Patrik Galeta, PhD., odborný asistent katedry antropologie Západočeské univerzity v Plzni. Statistickým metodám se věnuje v rámci demografických studií, na ZČU vede také kurz zpracování dat.
Ze školení si navíc odnesete více než 40 skriptů, které můžete použít pro zpracování dat ze svého výzkumu.