Osvojte si základní funkce jazyka R a balíčku dplyr pro transformaci dat a jejich přípravu pro statistickou analýzu.
V předchozích dílech naší série jsme prošli cestu od základních pojmů jazyka R přes import dat z různých statistických programů a jejich úpravu na tidy data až po práci s chybějícími hodnotami. Nyní je čas posunout se k další klíčové dovednosti – efektivní manipulaci s daty pomocí balíčku dplyr.
Balíček dplyr představuje jeden ze základních pilířů ekosystému tidyverse. Jeho síla spočívá v intuitivním přístupu k transformaci dat, který odpovídá způsobu, jakým o úpravě dat přemýšlíme.
Efektivní manipulace, kterou dplyr umožňuje, je pro výzkumnou práci s daty naprosto zásadní. Surové záznamy z experimentů často vyžadují filtrování, přeskupení nebo vytvoření nových proměnných před samotnou analýzou. Pro tyto operace nabízí dplyr jednoduché funkce, které by v základní verzi jazyka R vyžadovaly složitější kód.
Jejich použití demonstrujeme na datové sadě „bees_data“. Cílem měření je prozkoumat tuto alternativní hypotézu: aktivita včel (měřená počtem včel u úlu – „bee_count“) je signifikantně vyšší při teplotách („temperature“) nad 20 °C a oblačnosti („cloudiness“) pod 50 % v porovnání s obdobími, kdy je teplota pod 20 °C anebo oblačnost nad 50 %.V závěru článku pak demonstrujeme, jak se k upravené datové sadě dostat pomocí pipe operátoru.
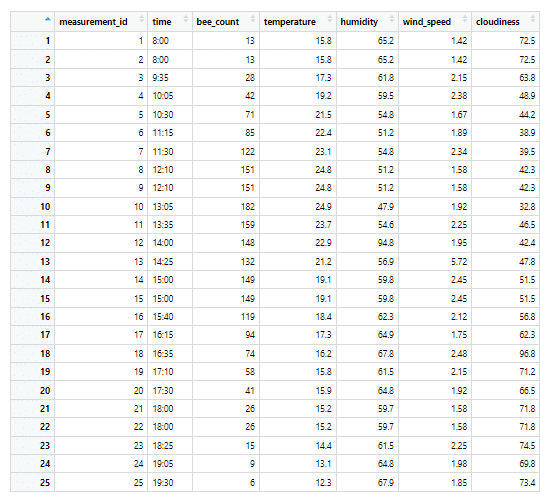
Výchozí dataset „bees_data“, se kterým budeme pracovat
Prvním krokem je načtení, popř. instalace ekosystému tidyverse:
# instalace a načtení celého tidyverse
install.packages("tidyverse")
library(tidyverse)Výběr proměnných (sloupců)
S funkcí ‚select()‘ vyberete (a případně přejmenujete) sloupce ve vašich datových sadách. První argument označuje dataset – v našem případě tedy „bees_data“. Další argumenty jsou pak sloupce, které chcete vybrat (a v rámci další analýzy s nimi pracovat):

# výběr jednoho sloupce („bee_count“)
bees_data_selection <- select(bees_data, bee_count)
# výběr více sloupců („bee_count“, „temperature“, „cloudiness“)
bees_data_selection <- select(bees_data, bee_count, temperature, cloudiness)Funkce ‚select()‘ nabízí několik užitečných operátorů pro výběr sloupců:
- : vybere všechny sloupce mezi zadanými sloupci (včetně zadaných sloupců),
- – odstraní zadané sloupce (resp. vybere všechny sloupce kromě zadaných),
- ! neguje výběr sloupců (např. nevybere žádné proměnné mezi zadanými sloupci).
# výběr všech sloupců mezi „measurement_id“ a „bee_count“:
bees_data_selection <- select(bees_data, measurement_id:bee_count)
# výběr všech sloupců mezi „measurement_id“ a „bee_count“ a mezi „humidity“ a „cloudiness“:
bees_data_selection <- select(bees_data, c(measurement_id:bee_count, humidity:cloudiness))
# výběr všech sloupců kromě „wind_speed“:
bees_data_selection <- select(bees_data, -wind_speed)
# výběr všech sloupců kromě těch mezi „humidity“ a „cloudiness“:
bees_data_selection <- select(bees_data, !humidity:cloudiness)Další pomocné funkce a logické operátory
Pro efektivnější práci s velkými datovými sadami můžete u funkce ‚select()‘ použít několik pomocných funkcí:
- ‚starts_with()‘ – vybere sloupce začínající určitým textem,
- ‚ends_with()‘ – vybere sloupce končící určitým textem,
- ‚contains()‘ – vybere sloupce obsahující určitý text,
- ‚matches()‘ – vybere sloupce odpovídající regulárnímu výrazu,
- ‚everything()‘ – vybere všechny zbývající sloupce.
# výběr všech sloupců začínajících na „wind“
bees_data_selection <- select(bees_data, starts_with("wind"))
# výběr všech sloupců končících na „count“
bees_data_selection <- select(bees_data, ends_with("count"))Využít lze i dva logické operátory:
- & (logické A) – vybere sloupce, které splňují všechny zadané podmínky,
- | (logické NEBO) – vybere sloupce, které splňují alespoň jednu zadanou podmínku; lze nahradit čárkou, která umožňuje zadat více podmínek.
# výběr sloupců, které obsahují „wind“ a končí na „speed“
bees_data_selection <- select(bees_data, contains("wind") & ends_with("speed"))
# výběr všech sloupců, které končí na „count“ nebo na „speed“
bees_data_selection <- select(bees_data, ends_with("count") | ends_with("speed"))Přejmenování sloupců (proměnných)
Funkce ‚select()‘ umožňuje sloupce nejen vybírat, ale i rovnou přejmenovat. K tomu slouží operátor = nebo funkce ‚rename()‘. V naší ukázce vybereme sloupce, které jsou relevantní pro statistickou analýzu alternativní hypotézy a proměnné pojmenujeme česky.
# výběr sloupců a jejich přejmenování pomocí operátoru =
bees_data_selection <- select(bees_data,
cas = time,
pocet_vcel = bee_count,
teplota = temperature,
vlhkost = humidity,
rychlost_vetru = wind_speed,
oblacnost = cloudiness)
# přejmenování sloupců pomocí funkce ‚rename‘ bez jejich selekce
bees_data_selection <- rename(bees_data,
cas = time,
pocet_vcel = bee_count,
teplota = temperature,
vlhkost = humidity,
rychlost_vetru = wind_speed,
oblacnost = cloudiness)Názvy proměnných (sloupců) můžete změnit podle potřeby už při pivotování dat (úpravě na tidy formát).
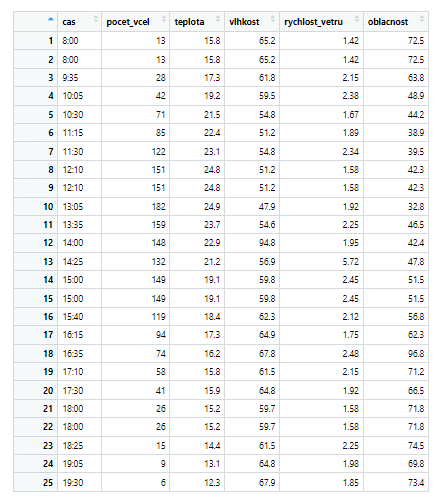
Upravený dataset bees_data_selection s relevantními proměnnými pro statistickou analýzu
Filtrování hodnot (řádků)
Funkce ‚filter()‘ slouží k výběru konkrétních řádků (pozorování) na základě zadaných podmínek. První argumentem funkce je název datasetu, dalšími argumenty jsou zmíněné podmínky.
V našem výzkumu aktivity včel ji využijeme k odstranění potenciálně problematických měření a k analýze specifických situací.
Pro filtrování dat se využívají relační operátory:
- == (rovná se),
- != (nerovná se),
- > (větší než),
- < (menší než),
- >= (větší nebo rovno),
- <= (menší nebo rovno).
# vyfiltrování měření s teplotou nad 20 °C
warm_measurements <- filter(bees_data_selection, teplota > 20)
# vyfiltrování měření v poledne (12:00)
noon_measurements <- filter(bees_data_selection, cas == "12:00")Pro kombinaci více podmínek používáme logické operátory zmíněné na předchozích řádcích, tedy & (logické A), | (logické NEBO) a ! (negace).
# měření s vysokou teplotou a nízkou oblačností
ideal_conditions <- filter(bees_data_selection, teplota > 20 & oblacnost < 50)
# měření brzy ráno nebo pozdě odpoledne
edge_times <- filter(bees_data_selection, cas <= "9:00" | cas >= "17:00")
# všechna měření kromě těch s nízkou aktivitou včel
active_bees <- filter(bees_data_selection, !pocet_vcel < 50)
# všechna měření kromě ranních a večerních
mid_day <- filter(bees_data_selection, !(cas <= "9:00" | cas >= "17:00"))Pro náš výzkum je důležité vyfiltrovat data, která by mohla zkreslit analýzu vztahu mezi teplotou a aktivitou včel. Zaměříme se proto na měření za standardních podmínek, které jsme na základě našich zkušeností definovali takto:
- rychlost větru nižší než 2,5 m/s (silný vítr snižuje aktivitu včel),
- vlhkost mezi 40 a 70 % (nízká vlhkost vede k předčasnému návratu včel do úlu, vysoká ztěžuje jejich termoregulaci),
- oblačnost pod 75 % (vysoká oblačnost narušuje cirkadiánní rytmus včel a zhoršuje jejich orientační schopnosti).
# vyfiltrování standardních podmínek pro analýzu
bees_data_filtered <- filter(bees_data_selection,
rychlost_vetru < 2.5,
(vlhkost >= 40 & vlhkost <= 70),
oblacnost < 75)
Dataset bees_data_filtered s relevantními proměnnými a odfiltrovanými extrémními hodnotami
Řazení hodnot (řádků)
S funkcí ‚arrange()‘ uspořádáte data podle jedné nebo více proměnných. Prvním argumentem je – jako v předchozích případech – název datové sady, druhým pak název proměnné pro vzestupné seřazení. Pro sestupné seřazení slouží pomocná funkce ‚desc()‘:
# seřazení podle počtu včel (vzestupně)
bees_by_count <- arrange(bees_data_filtered, pocet_vcel)
# seřazení podle teploty (sestupně)
bees_by_temp_desc <- arrange(bees_data_filtered, desc(teplota))Pro seřazení dat podle více kritérií stačí dané sloupce přidat jako další argumenty funkce ‚arrange()‘. Pokud jsou určité hodnoty u první zadané proměnné totožné (např. teplota 20 °C), u druhé proměnné se seřadí podle zadaného kritéria (např. počet včel se uspořádá sestupně).
# seřazení podle teploty (vzestupně) a počtu včel (sestupně)
bees_temp_count <- arrange(bees_data_filtered,
teplota,
desc(pocet_vcel))Řádky s chybějícími hodnotami, které jste se rozhodli zachovat (záleží na jejich typu – viz MCAR, MAR, MNAR), se standardně umístí na konec datasetu.
Tvorba nových proměnných
Při přípravě dat pro statistickou analýzu často potřebujeme vytvořit nové proměnné, které jsou odvozené od existujících dat. Typicky jde o situace, kdy je třeba:
- provést matematické operace s číselnými proměnnými,
- kategorizovat spojité proměnné do skupin,
- vytvořit binární (logické) proměnné na základě určitých podmínek,
- normalizovat nebo standardizovat hodnoty,
- kombinovat více proměnných do souhrnných indikátorů.
K tomu slouží funkce ‚mutate()‘, která umožňuje kombinovat různé výpočty a vytvořit v jednom kroku více sloupců.
Prvním argumentem funkce je název datové sady, druhý a další popisují nové proměnné, které tvoříme (a postup, jak se k hodnotám této proměnné dostat). Jejich syntax je obecně „nova-promenna = vypocet-hodnot“.
Nejjednodušší transformaci umožňují aritmetické operátory pro sčítaní (+), odečítání (-), násobení (*), dělení (/) a umocňování (^):
# základní operace
bees_math <- mutate(bees_data_filtered,
vlhkost_rel = vlhkost / 100,
rychlost_vetru_khm = rychlost_vetru * 3.6)
# kombinace více operací
bees_math <- mutate(bees_data_filtered,
normalizovana_teplota = (teplota - mean(teplota)) / sd(teplota))K tvorbě proměnných (a přiřazených hodnot) na základě určitých podmínek slouží pomocná funkce ‚case_when‘. Využívá se např. pro vytvoření kvalitativních (kategorických) proměnných. Její syntax je „podmínka ~ hodnota“; pokud je daná podmínka splněna, přiřadí se k nové proměnné určená hodnota.
Jak tuto pomocnou funkci použít v praxi? Vyjděme z alternativní hypotézy, kterou chceme otestovat: aktivita včel (měřená počtem včel u úlu – „bee_count“) je signifikantně vyšší při teplotách („temperature“) nad 20 °C a oblačnosti („cloudiness“) pod 50 % v porovnání s obdobími, kdy je teplota pod 20 °C nebo oblačnost nad 50 %.
Z toho vyplývá, že jednotlivá pozorování můžeme rozdělit podle proměnné „podmínky“. Ta může nabývat hodnot:
- „idealni“, pokud je hodnota teploty rovna nebo vyšší 20 °C a zároveň hodnota oblačnosti rovna nebo nižší 50 %,
- „suboptimalni“, pokud je teplota nižší než 20 °C, nebo v případě, že oblačnost přesahuje 50 % (tedy ve všech ostatních případech).
# rozdělení pozorování podle podmínek
bees_data_mutated <- mutate(bees_data_filtered,
podminky = case_when(
teplota >= 20 & oblacnost <= 50 ~ "idealni",
teplota < 20 | oblacnost > 50 ~ "suboptimalni"))
Proč v kódu uvádět podmínky všech nových kategorií?Při dvou kategoriích nám teoreticky stačí v kódu uvést pouze podmínky pro první kategorii. Pozorování, která tuto podmínku nesplňují (tedy všechna ostatní pozorování) lze označit argumentem „TRUE“. Pokud ale hodnoty u některých měření chybí, nemůžeme si být jisti, zda by toto chybějící měření patřilo mezi ta splňující podmínku. Je proto bezpečnější uvést podmínky i pro další kategorii. Před transformací vždy doporučujeme chybějící hodnoty správně zpracovat. |
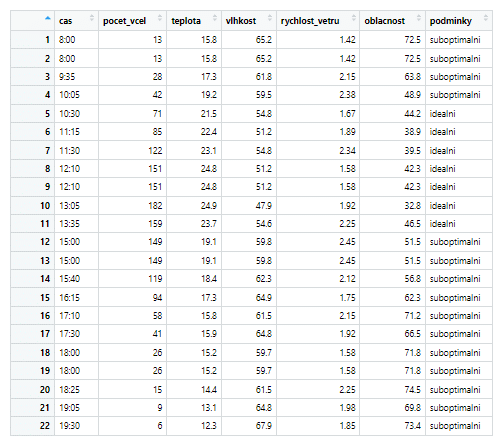
Dataset bees_data_mutated s relevantními proměnnými, odfiltrovanými extrémními hodnotami a novou proměnnou „podminky“
Pokud bychom chtěli rozdělit pozorování podle aktivity včel (na základě proměnné „pocet_vcel“) a podle denní doby (na základě proměnné „cas“), provedeme to podobně jako u proměnné „podminky“:
# rozdělení pozorování podle aktivity včel a denní doby
bees_data_mutated <- mutate(bees_data_filtered,
aktivita_vcel = case_when(
pocet_vcel < 30 ~ "nizka",
pocet_vcel < 100 ~ "stredni",
TRUE ~ "vysoka"),
denni_doba = case_when(
cas <= "10:00" ~ "rano",
cas <= "14:00" ~ "poledne",
cas <= "17:00" ~ "odpoledne",
TRUE ~ "vecer"))Odstranění duplicit
Při zpracování dat z výzkumu se často setkáváme s duplicitními záznamy. Vznikají např. opakovaným měřením, chybou při sběru dat nebo při jejich importu. Duplicity mohou významně ovlivnit výsledky analýzy, proto je důležité je identifikovat a správně s nimi naložit.
V balíčku dplyr k tomuto účelu slouží funkce ‚distinct()‘. První argument je název datové sady, druhý a další argumenty jsou názvy sloupců, ve kterých chceme duplicity identifikovat. Funkce odstraní duplicitní záznamy, ale vždy ponechá první výskyt každého záznamu (a ponechá jen uvedené sloupce). Pokud žádné sloupce neuvedeme, funkce odstraní řádky, které jsou duplicitní ve všech sloupcích.
Argument ‚.keep_all‘ s hodnotou ‚TRUE‘ pak zajistí, že se v datové sadě zachovají všechny sloupce.
# odstranění všech duplicit
bees_no_duplicities <- distinct(bees_data_mutated)
# odstranění duplicit u proměnných „počet včel“ a „oblačnost“ s ponecháním všech sloupců
bees_no_duplicities <- distinct(bees_data_mutated, pocet_vcel, oblacnost, .keep_all = TRUE)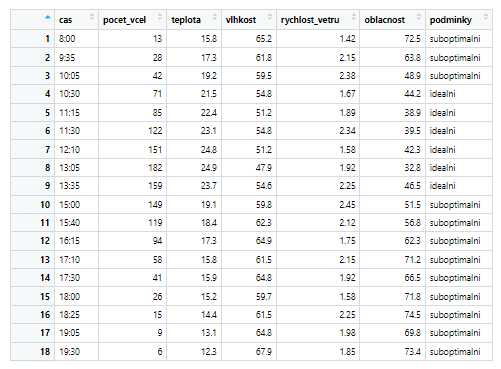
Dataset bees_no_duplicities s relevantními proměnnými, odfiltrovanými extrémními hodnotami, novou proměnnou „podminky“ a odstraněnými duplicitami
Seskupení a sumarizace dat
Při zpracování dat potřebujeme často určit charakteristiky různých skupin. Pro rozdělení datasetu slouží v jazyce R funkce ‚group_by()‘. První argument označuje datovou sadu, druhý a další argumenty jsou sloupce, podle jejichž hodnot vytvoříme skupiny.
Pokud seskupení aplikujeme např. na proměnnou „podminky“, následující sumarizace se spočítají pro skupiny hodnot této proměnné, tedy „idealni“ a „suboptimalni“:
# seskupení podle proměnné „podmínky“
bees_data_grouped <- group_by(bees_no_duplicities, podminky)Prvním argumentem funkce ‚summarize()‘ je datová sada, obvykle již seskupená pomocí ‚group_by()‘. Druhým a dalšími argumenty jsou pomocné funkce pro výpočty souhrnných statistik, které definujeme ve formátu: „nova_promenna = pomocna_funkce(nazev_sloupce)“. Některé z nejpoužívanějších pomocných funkcí jsou:
- ‚mean()‘ – aritmetický průměr,
- ‚median()‘ – medián,
- ‚sum()‘ – součet hodnot,
- ‚min()‘ – minimální hodnota,
- ‚max()‘ – maximální hodnota,
- ‚sd()‘ – směrodatná odchylka,
- ‚var()‘ – rozptyl,
- ‚n()‘ – počet řádků (pozorování – funkce nepřijímá žádné argumenty),
- ‚n_distinct()‘ – počet unikátních hodnot.
Argumentem pomocné funkce je název proměnné, pro kterou dané statistické charakteristiky počítáme.
Výstupem je datová sada s jedním řádkem pro každou skupinu a novými sloupci obsahujícími požadované souhrnné hodnoty.
# výpočet počtu pozorování a popisných statistik proměnné „počet včel“ pro ideální a suboptimální podmínky
bees_data_summary <- summarize(bees_data_grouped,
pocet_pozorovani = n(),
prumer_pocet_vcel = mean(pocet_vcel),
median_pocet_vcel = median(pocet_vcel),
smer_odchylka_pocet_vcel = sd(pocet_vcel),
rozptyl_pocet_vcel = var(pocet_vcel))
Dataset bees_data_summary
Podobné hodnoty směrodatných odchylek obou skupin (43,68 vs. 46,69) naznačují, že naši alternativní hypotézu lze ověřit pomocí t-testu. Kvůli malému vzorku pozorování (6 a 12) je ovšem vhodnější zvážit např. Mannův-Whitneyho test (neparametrická alternativa k t-testu).
Od datasetu k sumarizaci pomocí pipe operátoru
Pipe operátor (%>%) představuje elegantní způsob, jak zřetězit několik operací s daty do jediného přehledného toku. V našem příkladu s včelími daty nám umožní vytvořit jasnou sekvenci kroků od seskupení dat až po výpočet souhrnných statistik, což významně zvýší čitelnost kódu.
Data „protečou“ přes jednotlivé funkce a namísto tvorby řady datasetů se tak od syrových dat („bees_data“) dostaneme rovnou k výpočtu popisných statistik ideálních a suboptimálních pozorování („bees_data_summary“):
bees_data_summary <- bees_data %>%
# přejmenování sloupců do češtiny a výběr relevantních proměnných
select(
cas = time,
pocet_vcel = bee_count,
teplota = temperature,
vlhkost = humidity,
rychlost_vetru = wind_speed,
oblacnost = cloudiness) %>%
# filtrování měření za nestandardních podmínek
filter(
rychlost_vetru < 2.5,
vlhkost >= 40 & vlhkost <= 70,
oblacnost < 75) %>%
# vytvoření nové kategoriální proměnné podle atmosférických podmínek
mutate(podminky = case_when(
teplota >= 20 & oblacnost <= 50 ~ "idealni",
teplota < 20 | oblacnost > 50 ~ "suboptimalni")) %>%
# odstranění případných duplicitních měření
distinct() %>%
# seskupení dat podle typu podmínek
group_by(podminky) %>%
# výpočet souhrnných statistik pro každou skupinu
summarize(
pocet_pozorovani = n(),
prumer_pocet_vcel = mean(pocet_vcel),
median_pocet_vcel = median(pocet_vcel),
smer_odchylka_pocet_vcel = sd(pocet_vcel),
rozptyl_pocet_vcel = var(pocet_vcel))Naučte se ovládat jazyk R pod dohledem zkušeného lektora
Kurz ovládání programovacího jazyka R pořádáme pravidelně v Praze i na dalších místech. Během 1denního kurzu se kromě základních funkcí naučíte do jazyka R data importovat, upravit je, analyzovat a nakonec vizualizovat.
Lektorem kurzu je Mgr. Patrik Galeta, PhD., odborný asistent katedry antropologie Západočeské univerzity v Plzni. Statistickým metodám se věnuje v rámci demografických studií, na ZČU vede také kurz zpracování dat.
Ze školení si navíc odnesete více než 40 skriptů, které můžete použít pro zpracování dat ze svého výzkumu.