Začínáte se zpracováním dat v jazyce R? Přečtěte si předchozí díly série:
- 1. díl: základní pojmy a funkce
- 2. díl: import dat z Excelu, TIBCO Statistica a SPSS
- 3. díl: import dat z aplikací SAS, MATLAB a Stata
- 4. díl: základní úpravy struktury dat (v tidyr)
V předchozím článku jsme se věnovali základním úpravám datových struktur. Ukázali jsme si, jak (a proč) pomocí balíčku tidyr transformovat data do uspořádané podoby (tidy data) a jak pracovat s tibble formátem.
Při práci s reálnými daty z výzkumu je jednou z hlavních výzev zpracování chybějících hodnot. To, jak s nimi naložíte, ovlivní přesnost statistické analýzy a v konečném důsledku i šanci na (ne)potvrzení vaší alternativní hypotézy.
Řadu užitečných funkcí pro jejich zpracování nabízí balíček tidyr, který je součástí tidyverse:
# instalace a načtení celého tidyverse
install.packages("tidyverse")
library(tidyverse)Druhy chybějících hodnot
Pokud data chybí už v původním záznamu měření (např. csv souboru), je potřeba je zpracovat při importu do jazyka R. K tomu slouží zpravidla argument ‚na‘ funkcí pro import datových setů. Podrobné informace najdete zde:
- import dat z Excelu,
- import dat z TIBCO Statistica (formát csv a tsv),
- import dat z aplikace SPSS,
- import dat z aplikace SAS/STAT,
- import dat z Matlabu,
- import dat z aplikace STATA.
Proč vůbec řešit chybějící hodnoty?Neoznačené chybějící hodnoty (prázdné buňky) mohou způsobit chyby a nesprávné výsledky ve výpočtech, protože software je nemusí rozpoznat jako chybějící.  |
V programovacím jazyce R se chybějící data označují zpravidla jako NA (Not Available). Před jejich dalším zpracováním je klíčové porozumět jejich povaze. Chybějící data rozdělujeme následovně:
- MCAR (Missing Completely at Random) – data chybí zcela náhodně, bez jakékoli souvislosti s ostatními proměnnými nebo chybějícími hodnotami. Důvodem je např. ztráta části dotazníků, selhání měřícího přístroje nebo opomenutí některých položek při vyplňování dotazníku.
- MAR (Missing at Random) – hodnoty nechybí kvůli jejich povaze, ale kvůli spříznění s jinou proměnnou v datové sadě. Např. ženy častěji neuvádějí svou váhu, ať je jakákoliv – absence hodnoty proměnné „váha“ proto souvisí s hodnotou „žena“ proměnné „pohlaví“, ale už ne s hodnotou samotné proměnné „váha“.
- MNAR (Missing not at Random) – hodnoty chybí systematicky a pravděpodobnost jejich absence přímo souvisí se samotnou hodnotou dané proměnné. Např. pacienti s těžkou depresí častěji neodpoví na otázky o duševním zdraví než pacienti s lehkou depresí, protože těžký průběh onemocnění jim v tom fakticky zabrání.
Zpracování různých typů chybějících hodnot shrnuje tato tabulka:
| Typ chybějících hodnot | Řešení s vhodnou funkcí v R |
| MCAR | Ponechání měření s chybějícími daty Odstranění měření (řádků) s chybějícími daty → drop_na() Nahrazení chybějících dat specifickou hodnotou → replace_na() |
| MAR | Doplnění chybějících dat předchozí/následující hodnotou → fill() Nahrazení chybějících dat specifickou hodnotou → replace_na() |
| MNAR | Pokročilé modelování Volba odlišného experimentálního designu |
V následujících příkladech budeme pracovat s datasetem různých vyšetření u pacientů s kardiovaskulárními nemocemi:
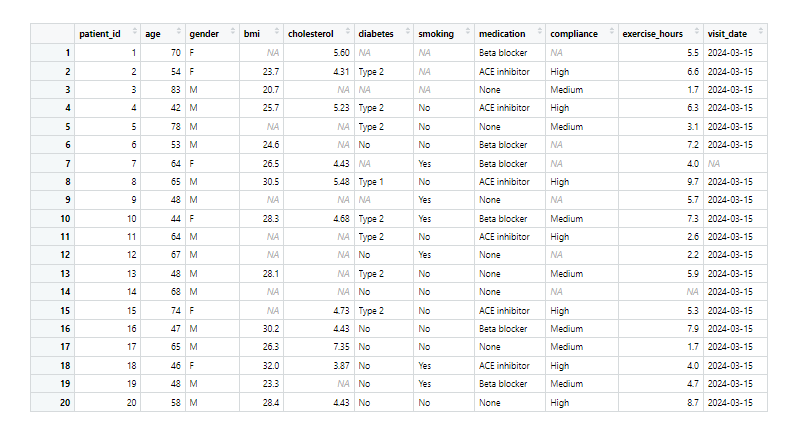
Datová sada „patients“ v tidy data formátu
Příklad – druhy chybejících dat v sadě „patients“Určení druhu chybějících dat závisí na pojetí výzkumného designu a charakteru jednotlivých úkonů. U datasetu „patients“ tak můžeme původ chybějících hodnot u různých proměnných určit takto:
|
Podíl chybějících hodnot
Pro zjištění podílu chybějících hodnot v datové sadě můžete využít několik funkcí z ekosystému tidyverse:
- ‚summarise‘ – funkce pro výpočet souhrnných statistik,
- ‚across‘ – aplikuje funkci na všechny sloupce,
- ‚everything‘ – vybere všechny sloupce v datasetu,
- ‚is.na‘ – identifikuje chybějící hodnoty (vrací TRUE/FALSE),
- ‚mean‘ – počítá průměr (v tomto případě podíl TRUE hodnot).
# podíl chybějících hodnot v celé datové sadě
patients %>%
summarise(across(everything(), ~mean(is.na(.)) * 100))Odstranění měření s chybějícími hodnotami
K odstranění chybějících hodnot (resp. celých měření – řádků – s chybějícími hodnotami) přistupte, pokud:
- jde o data typu MCAR,
- máte dostatečně velký vzorek, abyste si mohli dovolit některá měření vyřadit,
- se chybějící hodnoty vyskytují jen u malého procenta měření (zpravidla méně než 5–10 %),
- v daném měření chybí hodnoty u tzv. klíčové proměnné – tedy proměnné, kterou v rámci statistické analýzy vyhodnocujeme (ani zde by ale podíl chybějících hodnot neměl překročit zmíněných 5–10 %).
Pro odstranění řádků s chybějícími hodnotami slouží funkce ‚drop_na‘. První argument označuje dataset, ze kterého chybějící data odstraníme. Bez dalších argumentů dojde k eliminaci všech řádků s chybějícími hodnotami.
Pokud jako další argumenty použijete názvy určitých proměnných (sloupců) v datasetu, odstraní se pouze ty řádky, u kterých v daných proměnných chybí hodnoty:
# odstranění všech řádků s chybějící proměnnou z datasetu „patients“
patients <- drop_na(patients)
# odstranění všech řádků s chybějící proměnnou ve sloupci „exercise_hours“
patients <- drop_na(patients, exercise_hours)
# odstranění všech řádků s chybějící proměnnou ve sloupcích „exercise_hours“ a „cholesterol“
patients <- drop_na(patients, exercise_hours, cholesterol)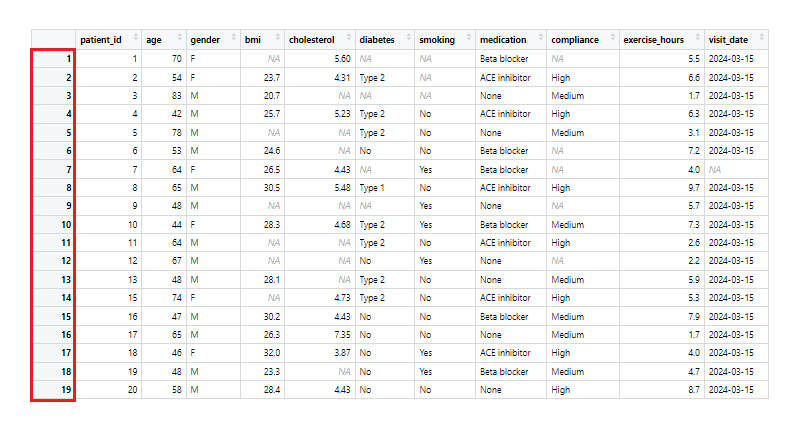
Datová sada „patients“ bez chybějících dat podle proměnné „exercise_hours“ (u proměnné „cholesterol“ jsme měření s chybějícími daty ponechali, protože jejich podíl je 40 %). Měření s chybějícími hodnotami u proměnné „exercise_hours“ odstraníme pouze v případě, že tuto proměnnou budeme dále vyhodnocovat v rámci statistické analýzy.
Nahrazení (imputace) chybějících hodnot
Nahrazení chybějících dat se hodí ve chvíli, kdy:
- absence chybějících hodnot typu MCAR a MAR je vyšší než 5–10% a eliminace daných měření by mohla vést ke ztrátě důležitých informací,
- potřebujete kvůli zachování statistické síly testu zachovat i velikost vzorku.
Povaha nahrazení chybějící hodnoty se odvíjí od typu proměnné a druhu chybějících dat:
- Spojité proměnné – pro typ MCAR lze chybějící hodnoty nahradit průměrem, mediánem nebo predikovanou hodnotou z regresního modelu (tomu se budeme věnovat v jednom z následujících článků). Pro typy MAR a MNAR jsou vhodnější metodou algoritmy k-Nearest Neighbors imputace (kNN) a Expectation-Maximization (EM), případně vícenásobná imputace, která generuje několik možných hodnot.
- Diskrétní proměnné – MCAR hodnoty lze nahradit nejčastější hodnotou (modus) nebo zaokrouhlenou průměrnou hodnotou. V případě MAR je vhodnější využít regresní model nebo metodu kNN. Pro MNAR lze modelovat mechanismus chybění dat nebo využít vícenásobnou imputaci.
- Ordinální proměnné – u chybějících hodnot MCAR využijte nahrazení mediánem nebo střední hodnotou stupnice. Pro chybějící data typu MAR je vhodné využít regresní modely nebo sofistikované metody vícenásobné imputace. V případě MNAR lze využít bayesovské metody vícenásobné imputace.
- Nominální proměnné – u MCAR hodnot je možné použít nahrazení nejčastější hodnotou (modus) nebo zavést kategorii „neznámý“ či „neuvedeno„. Pro chybějící data typu MAR je efektivní využití KNN nebo vícenásobné imputace. U MNAR lze zvolit speciální kategorie nebo použít náhradní modelování pro chybějící a nechybějící části zvlášť.
Nahrazení sousedními hodnotami – funkce ‚fill‘
U časových řad či určitých kategoriálních proměnných můžete chybějící data nahradit sousedními hodnotami. V případě naší tabulky můžeme takto přistoupit k doplnění chybějících dat u proměnných:
- „visit_date“, pokud víme, že všichni pacienti v klinické studii měli navštívit lékaře ve stejný den (a u pacientů bez zapsaného data návštěvy máme záznamy měření),
- „diabetes“, máme-li informace o (ne)přítomnosti cukrovky z nedávných návštěv (a předpokládáme, že již nemocní se nevyléčili a že u pacientů bez diabetu k jeho rozvoji nedošlo).
K doplnění prázdných polí podle vedlejší hodnoty slouží funkce ‚fill‘. Podobně jako u funkce ‚drop_na‘ je prvním argumentem název datové sady, kterou upravujeme. Pokud jako další argumenty použijeme názvy sloupců (proměnných), dojde u nich k doplnění chybějících hodnot (bez specifikace sloupců se doplní chybějící hodnoty v celé tabulce).
Poslední argumentem funkce je ‚.direction‘, který určuje směr vyplňování hodnot:
- ‚down‘ (výchozí hodnota) – prázdná místa se vyplní předcházejícími hodnotami směrem dolů,
- ‚up‘ – prázdná místa se vyplní hodnotami ze záznamů pod nimi, tedy směrem nahoru,
- ‚downup‘ – funkce nejprve doplní prázdná místa směrem dolů, následně doplní zbývající chybějící hodnoty směrem nahoru; tento přístup je vhodný, pokud chcete zajistit doplnění hodnot z obou stran v rámci celé datové sady,
- ‚updown‘ – funkce nejprve doplní prázdná místa směrem nahoru, poté doplní zbývající chybějící hodnoty směrem dolů; užitečné např. při zpracování dat, kde upřednostňujeme hodnoty z pozdějších záznamů.
# doplnění chybějících dat u proměnné „visit_date“ podle sousedních hodnot
patients <- fill(patients, visit_date, .direction = "downup")
Upravená datová sada „patients“ s doplněnými hodnotami u proměnné „visit_date“ (víme, že všechny návštěvy proběhly 15. 3. 2024)
Nahrazení specifickými hodnotami – funkce ‚replace_na‘
Funkce ‚replace_na‘ nahradí chybějící data ve zvolených sloupcích specifickými hodnotami.
Prvním argumentem funkce je název datové sady. Druhý a další argumenty mohou být názvy sloupců (proměnných), ve kterých chybějící data nahradíte hodnotou argumentu.
V našem příkladu bychom za chybějící data u proměnných „diabetes“ a „smoking“ mohli vložit hodnotu „Unknown“, pokud stav těchto pacientů skutečně neznáme.
Pozor, v syntaxi je třeba použít funkci ‚list‘. Umožní vám zadat jednu a více proměnných (sloupců) ve formě seznamu a přiřadit k nim specifické hodnoty, kterými chybějící data nahradíte.
# doplnění chybějících dat u proměnné „diabetes“ hodnotou „Unknown“
patients <- replace_na(patients, list(diabetes = "Unknown"))
# doplnění chybějících dat u proměnných „diabetes“ a „smoking“ hodnotou „Unknown“
patients <- replace_na(patients, list(diabetes = "Unknown", smoking = "Unknown"))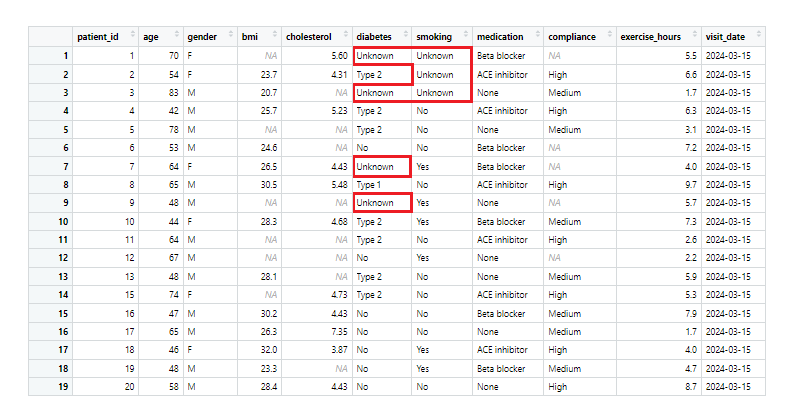
Upravená datová sada „patients“ s doplněnými hodnotami („Unknown“) u proměnných „diabetes“ a „smoking“
Na místo chybějících hodnot cholesterolu (typ MCAR) vložíme medián, spočítaný ze známých hodnot této proměnné. V použitém kódu níže najdete funkci ‚median‘ pro výpočet mediánové hodnoty, která obsahuje tyto argumenty:
- ‚dataset$proměnná‘ (v našem případě ‚patients$cholesterol‘) – určuje, z jakých dat se medián spočítá,
- ‚na.rm‘ – určuje, zda má funkce medián při výpočtu ignorovat prázdné buňky (v našem případě proto argument nabývá hodnoty ‚TRUE‘ – pokud by ‚na.rm‘ chybělo nebo nabývalo hodnoty ‚FALSE‘, chybějící hodnoty nahradí označení ‚NA‘).
# doplnění chybějících dat u proměnné „cholesterol“ hodnotou mediánu
patients <- replace_na(patients, list(cholesterol = median(patients$cholesterol, na.rm = TRUE)))
Upravená datová sada „patients“ s doplněnými hodnotami mediánu proměnné „cholesterol“
Rozšiřování datových sad
Při analýze dat často potřebujete vytvořit všechny možné kombinace hodnot proměnných nebo doplnit chybějící kombinace. Balíček tidyr nabízí pro tyto operace dvě klíčové funkce – ‚expand‘ a ‚complete‘.
Funkce ‚expand‘ vytváří novou datovou sadu se všemi možnými kombinacemi existujících hodnot zadaných proměnných. To je užitečné například při:
- přípravě dat pro vizualizaci, kdy potřebujete zobrazit i kombinace, které v původních datech chybí,
- analýze interakcí mezi proměnnými,
- kontrole úplnosti datové sady.
V našem případě můžeme chtít vytvořit všechny možné kombinace proměnných „diabetes“ a „smoking“. Tím zjistíte, zda máte v datové sadě kompletní spektrum možných stavů pacientů pro analýzu.
Pokud např. chybí pozorování pacientů s diabetem typu 1, kteří kouří (nebo nemáme dostatečný počet pozorování), může dojít ke zkreslení výsledků studie o rizicích vlivu kouření na zdravotní stav pacientů cukrovkou 1. druhu.
První argument funkce je název datové sady, další argumenty názvy všech sloupců (proměnných), jejichž hodnoty chcete zkombinovat.
# vytvoření všech kombinací z existujících hodnot proměnných „diabetes“ a „smoking“ z datasetu „patients“
patients_expanded <- expand(patients, diabetes, smoking)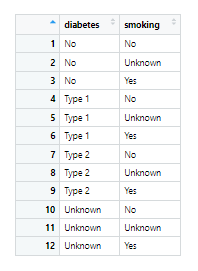
Nová datová sada „patients_expanded“ se všemi možnými kombinacemi hodnot proměnných „smoking“ („Yes“, „No“ a „Unknown“) a „diabetes“ („No“, „Type 1“, „Type 2“ a „Unknown“) v sadě „patients“ – celkem 3 × 4 = 12 kombinací
Jak vidíte, výsledný dataset „patients_expanded“ nám nezodpoví, které kombinace hodnot proměnných „diabetes“ a „smoking“ v tabulce „patients“ chybí (zobrazuje všechny možné kombinace, včetně těch, které v původní datové sadě neexistují).
Musíme si proto pomoct funkcí ‚anti_join‘ z balíčku dplyr (tomu se blíže budeme věnovat v následujících článcích). Umožní vám z datasetu „patients_expanded“ vyfiltrovat kombinace, které v původní datové sadě („patients“) chybí. Mezi základní argumenty funkce patří:
- názvy porovnávaných datových sad, v našem případě „patients_expanded“ a „patients“,
- by – určuje, jaké proměnné budeme v porovnávat (v našem případě „diabetes“ a „smoking“).
# vyfiltrování neexistujících kombinací hodnot proměnných „diabetes“ a „smoking“ a jejich uložení do datové sady „missing_combinations“
missing_combinations <- anti_join(patients_expanded, patients, by = c("diabetes", "smoking"))
Datová sada „missing_combinations“ zobrazuje, které kombinace hodnot proměnných „diabetes“ a „smoking“ chybí v datasetu „patients“
Pokud chcete do datasetu doplnit neexistující kombinace (s tím, že hodnoty ostatních proměnných budou chybět), stačí využít funkci ‚complete‘.
První argument je název rozšiřované tabulky (v našem případě „patients“), druhý a další argumenty názvy proměnných, jejichž neexistující kombinace se do datasetu doplní (tedy „diabetes“ a „smoking“).
# doplnění neexistujících kombinací hodnot proměnných „diabetes“ a „smoking“ do datové sady „patients“
patients <- complete(patients, smoking, diabetes)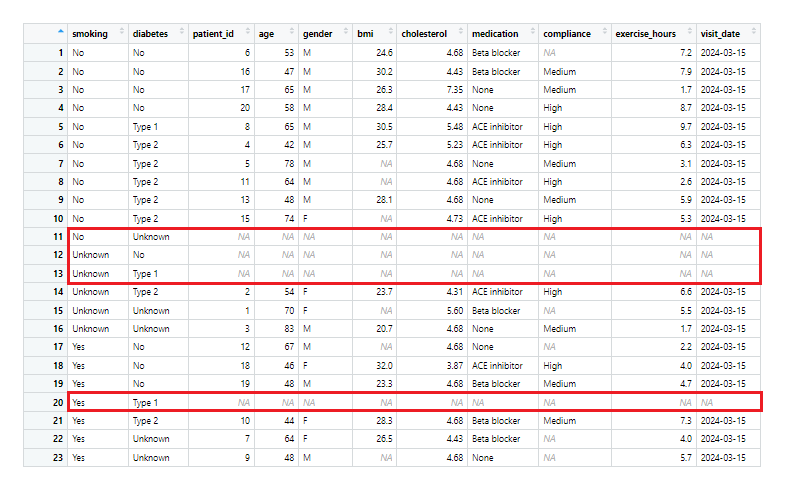
Datová sada „patients“ rozšířená o kombinace proměnných „smoking“ a „diabetes“
Naučte se ovládat jazyk R pod dohledem zkušeného lektora
Kurz ovládání programovacího jazyka R pořádáme pravidelně v Praze i na dalších místech. Během 1denního kurzu se kromě základních funkcí naučíte do jazyka R data importovat, upravit je, analyzovat a nakonec vizualizovat.
Lektorem kurzu je Mgr. Patrik Galeta, PhD., odborný asistent katedry antropologie Západočeské univerzity v Plzni. Statistickým metodám se věnuje v rámci demografických studií, na ZČU vede také kurz zpracování dat.
Ze školení si navíc odnesete více než 40 skriptů, které můžete použít pro zpracování dat ze svého výzkumu.